

前言
计算机系统中有很多独占性的资源,在同一时刻只能每个资源只能由一个进程使用,我们之前经常提到过打印机,这就是一个独占性的资源,同一时刻不能有两个打印机同时输出结果,否则会引起文件系统的瘫痪。所以,操作系统具有授权一个进程单独访问资源的能力。
两个进程独占性的访问某个资源,从而等待另外一个资源的执行结果,会导致两个进程都被阻塞,并且两个进程都不会释放各自的资源,这种情况就是 死锁(deadlock)。
死锁可以发生在任何层面,在不同的机器之间可能会发生死锁,在数据库系统中也会导致死锁,比如进程 A 对记录 R1 加锁,进程 B 对记录 R2 加锁,然后进程 A 和 B 都试图把对象的记录加锁,这种情况下就会产生死锁。
下面我们就来讨论一下什么是死锁、死锁的条件是什么、死锁如何预防、活锁是什么等。
首先你需要先了解一个概念,那就是资源是什么
资源
大部分的死锁都和资源有关,在进程对设备、文件具有独占性(排他性)时会产生死锁。我们把这类需要排他性使用的对象称为资源(resource)。资源主要分为 可抢占资源和不可抢占资源
可抢占资源和不可抢占资源
资源主要有可抢占资源和不可抢占资源。可抢占资源(preemptable resource) 可以从拥有它的进程中抢占而不会造成其他影响,内存就是一种可抢占性资源,任何进程都能够抢先获得内存的使用权。
不可抢占资源(nonpreemtable resource) 指的是除非引起错误或者异常,否则进程无法抢占指定资源,这种不可抢占的资源比如有光盘,在进程执行调度的过程中,其他进程是不能得到该资源的。
死锁与不可抢占资源有关,虽然抢占式资源也会造成死锁,不过这种情况的解决办法通常是在进程之间重新分配资源来化解。所以,我们的重点自然就会放在了不可抢占资源上。
下面给出了使用资源所需事件的抽象顺序

如果在请求时资源不存在,请求进程就会强制等待。在某些操作系统中,当请求资源失败时进程会自动阻塞,当自资源可以获取时进程会自动唤醒。在另外一些操作系统中,请求资源失败并显示错误代码,然后等待进程等待一会儿再继续重试。
请求资源失败的进程会陷入一种请求资源、休眠、再请求资源的循环中。此类进程虽然没有阻塞,但是处于从目的和结果考虑,这类进程和阻塞差不多,因为这类进程并没有做任何有用的工作。
请求资源的这个过程是很依赖操作系统的。在一些系统中,一个 request 系统调用用来允许进程访问资源。在一些系统中,操作系统对资源的认知是它是一种特殊文件,在任何同一时刻只能被一个进程打开和占用。资源通过 open 命令进行打开。如果文件已经正在使用,那么这个调用者会阻塞直到当前的占用文件的进程关闭文件为止。
资源获取
对于一些数据库系统中的记录这类资源来说,应该由用户进程来对其进行管理。有一种管理方式是使用信号量(semaphore) 。这些信号量会初始化为 1 。互斥锁也能够起到相同的作用。
这里说一下什么是
互斥锁(Mutexes):在计算机程序中,
互斥对象(mutex)是一个程序对象,它允许多个程序共享同一资源,例如文件访问权限,但并不是同时访问。需要锁定资源的线程都必须在使用资源时将互斥锁与其他线程绑定(进行加锁)。当不再需要数据或线程结束时,互斥锁设置为解锁。
下面是一个伪代码,这部分代码说明了信号量的资源获取、资源释放等操作,如下所示
typedef int semaphore;
semaphore aResource;
void processA(void){
down(&aResource);
useResource();
up(&aResource);
}上面显示了一个进程资源获取和释放的过程,但是一般情况下会存在多个资源同时获取锁的情景,这样该如何处理?如下所示
typedef int semaphore;
semaphore aResource;
semaphore bResource;
void processA(void){
down(&aResource);
down(&bResource);
useAResource();
useBResource();
up(&aResource);
up(&bResource);
}对于单个进程来说,并不需要加锁,因为不存在和这个进程的竞争条件。所以单进条件下程序能够完好运行。
现在让我们考虑两个进程的情况,A 和 B ,还存在两个资源。如下所示
typedef int semaphore;
semaphore aResource;
semaphore bResource;
void processA(void){
down(&aResource);
down(&bResource);
useBothResource();
up(&bResource);
up(&aResource);
}
void processB(void){
down(&aResource);
down(&bResource);
useBothResource();
up(&bResource);
up(&aResource);
}在上述代码中,两个进程以相同的顺序访问资源。在这段代码中,一个进程在另一个进程之前获取资源,如果另外一个进程想在第一个进程释放之前获取资源,那么它会由于资源的加锁而阻塞,直到该资源可用为止。
在下面这段代码中,有一些变化
typedef int semaphore;
semaphore aResource;
semaphore bResource;
void processA(void){
down(&aResource);
down(&bResource);
useBothResource();
up(&bResource);
up(&aResource);
}
void processB(void){
down(&bResource); // 变化的代码
down(&aResource); // 变化的代码
useBothResource();
up(&aResource); // 变化的代码
up(&bResource); // 变化的代码
}这种情况就不同了,可能会发生同时获取两个资源并有效地阻塞另一个过程,直到完成为止。也就是说,可能会发生进程 A 获取资源 A 的同时进程 B 获取资源 B 的情况。然后每个进程在尝试获取另一个资源时被阻塞。
在这里我们会发现一个简单的获取资源顺序的问题就会造成死锁,所以死锁是很容易发生的,所以下面我们就对死锁做一个详细的认识和介绍。
死锁
如果要对死锁进行一个定义的话,下面的定义比较贴切
如果一组进程中的每个进程都在等待一个事件,而这个事件只能由该组中的另一个进程触发,这种情况会导致死锁。
简单一点来表述一下,就是每个进程都在等待其他进程释放资源,而其他资源也在等待每个进程释放资源,这样没有进程抢先释放自己的资源,这种情况会产生死锁,所有进程都会无限的等待下去。
换句话说,死锁进程结合中的每个进程都在等待另一个死锁进程已经占有的资源。但是由于所有进程都不能运行,它们之中任何一个资源都无法释放资源,所以没有一个进程可以被唤醒。这种死锁也被称为资源死锁(resource deadlock)。资源死锁是最常见的类型,但不是所有的类型,我们后面会介绍其他类型,我们先来介绍资源死锁
资源死锁的条件
针对我们上面的描述,资源死锁可能出现的情况主要有
- 互斥条件:每个资源都被分配给了一个进程或者资源是可用的
- 保持和等待条件:已经获取资源的进程被认为能够获取新的资源
- 不可抢占条件:分配给一个进程的资源不能强制的从其他进程抢占资源,它只能由占有它的进程显示释放
- 循环等待:死锁发生时,系统中一定有两个或者两个以上的进程组成一个循环,循环中的每个进程都在等待下一个进程释放的资源。
发生死锁时,上面的情况必须同时会发生。如果其中任意一个条件不会成立,死锁就不会发生。可以通过破坏其中任意一个条件来破坏死锁,下面这些破坏条件就是我们探讨的重点
死锁模型
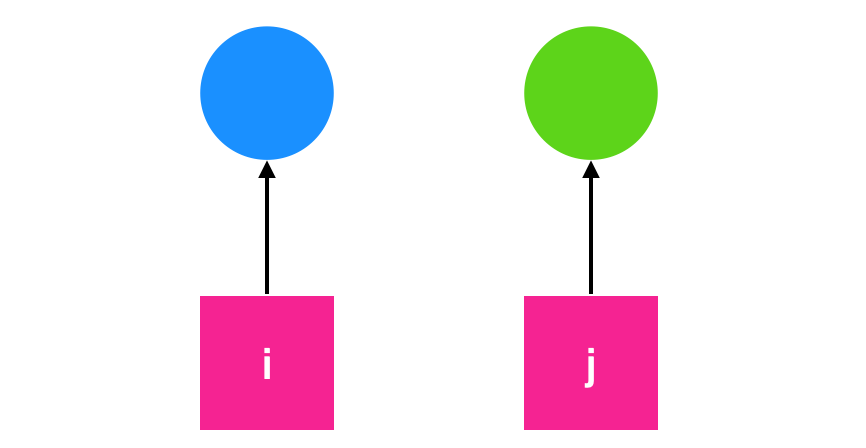
Holt 在 1972 年提出对死锁进行建模,建模的标准如下:
- 圆形表示进程
- 方形表示资源
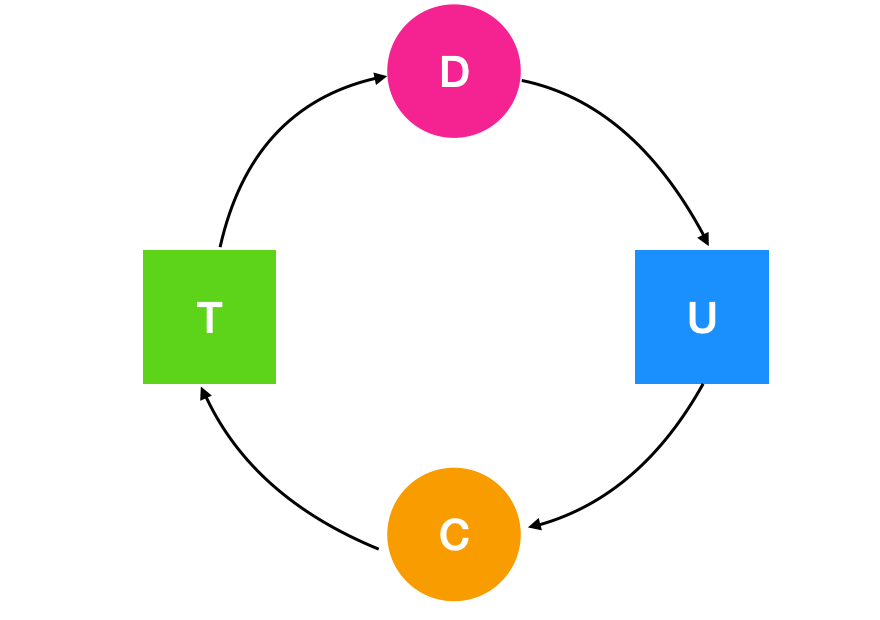
从资源节点到进程节点表示资源已经被进程占用,如下图所示
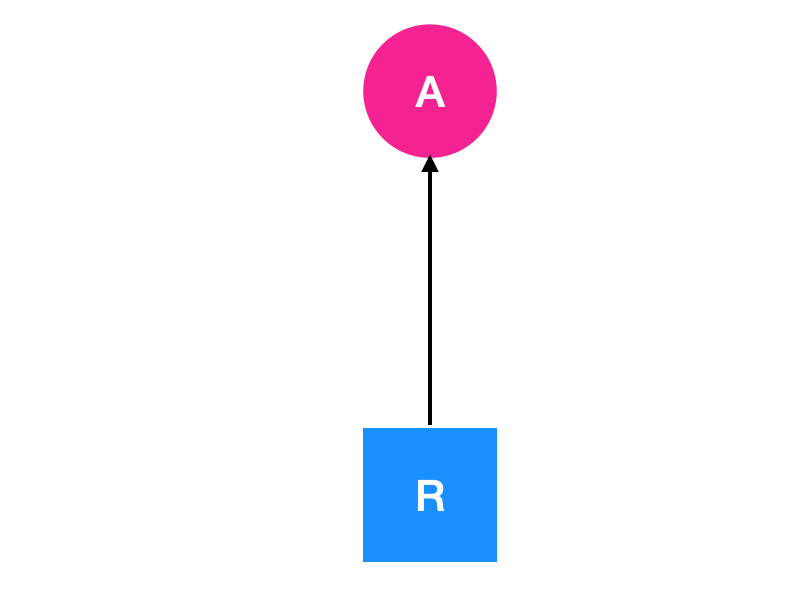
在上图中表示当前资源 R 正在被 A 进程所占用
由进程节点到资源节点的有向图表示当前进程正在请求资源,并且该进程已经被阻塞,处于等待这个资源的状态
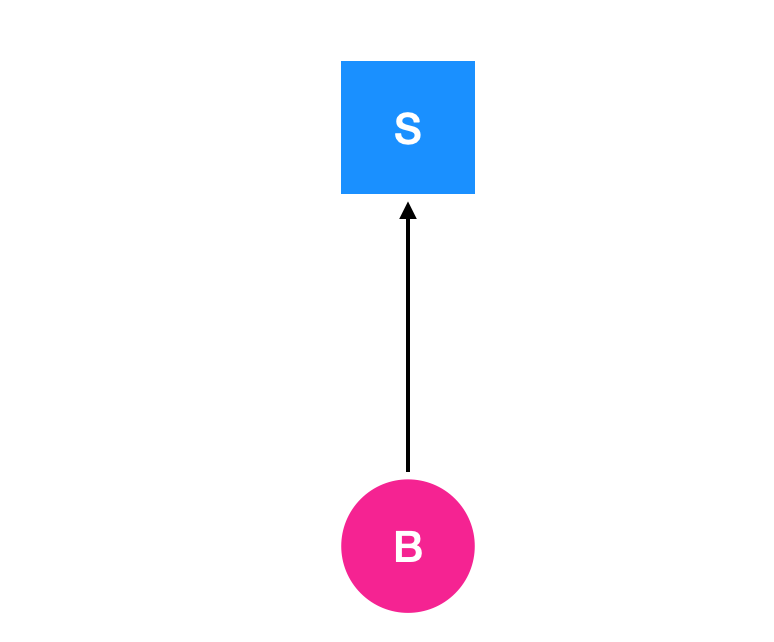
在上图中,表示的含义是进程 B 正在请求资源 S 。Holt 认为,死锁的描述应该如下
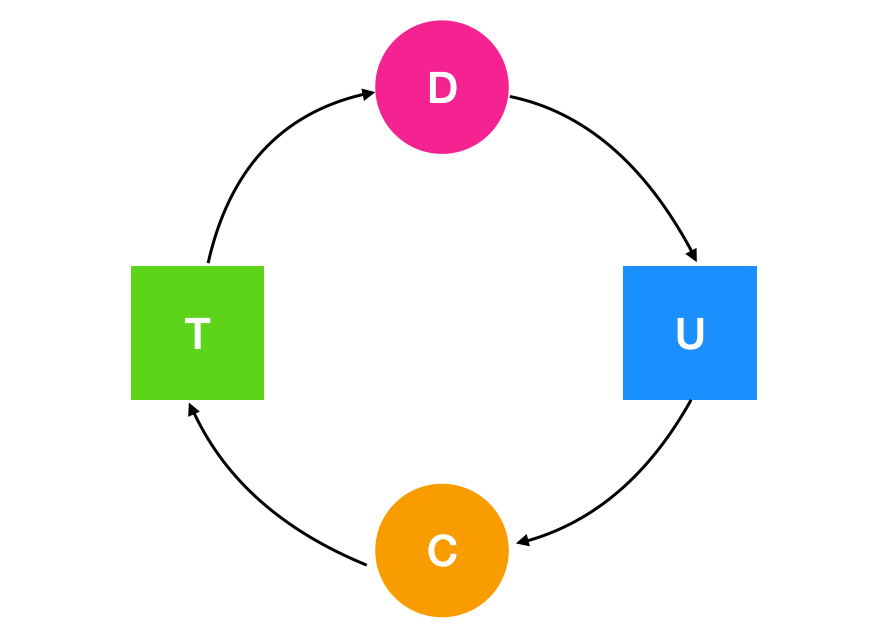
这是一个死锁的过程,进程 C 等待资源 T 的释放,资源 T 却已经被进程 D 占用,进程 D 等待请求占用资源 U ,资源 U 却已经被线程 C 占用,从而形成环。
总结一点:吃着碗里的看着锅里的容易死锁
那么如何避免死锁呢?我们还是通过死锁模型来聊一聊
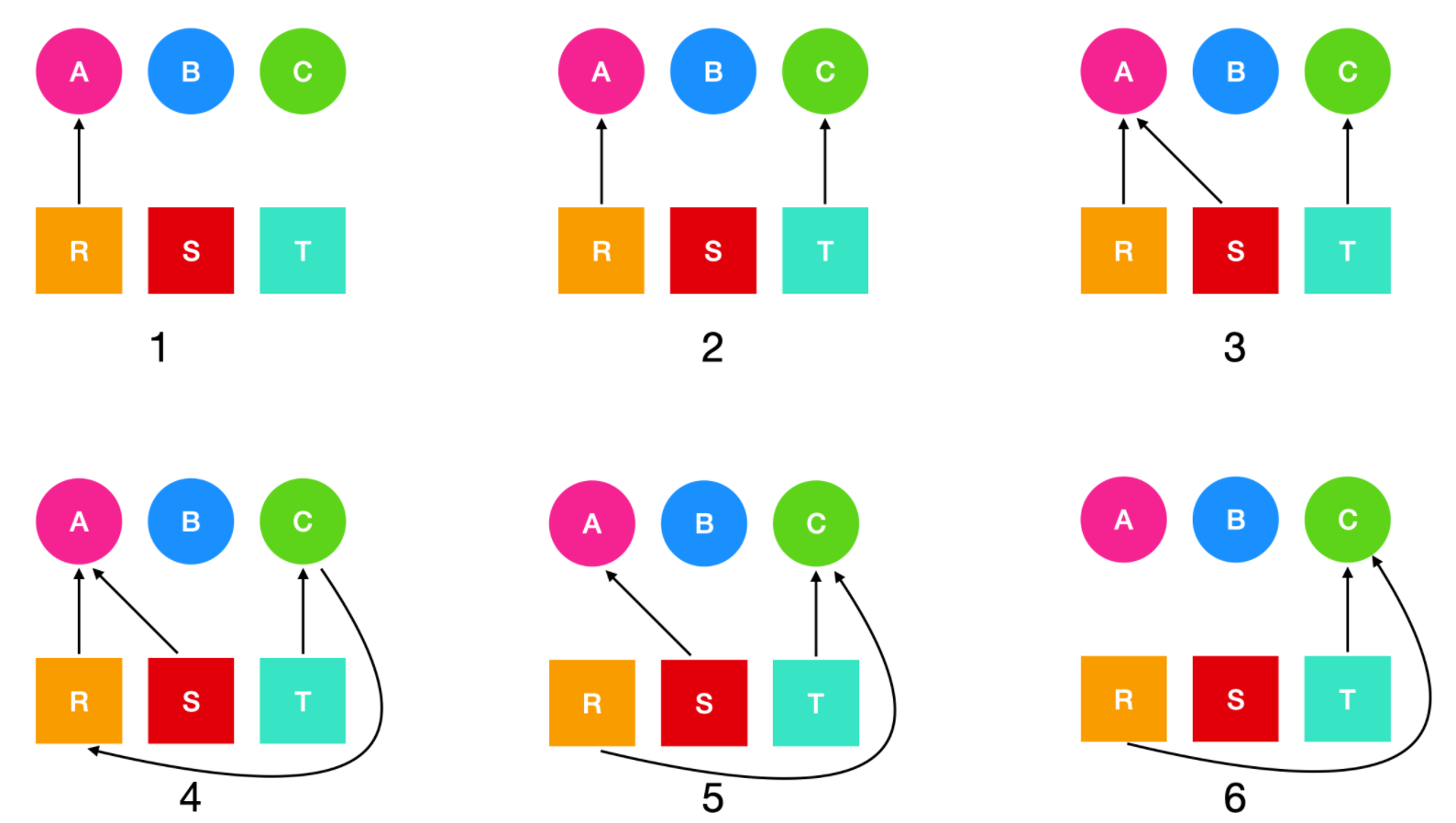
假设有三个进程 (A、B、C) 和三个资源(R、S、T) 。三个进程对资源的请求和释放序列如下图所示

操作系统可以任意选择一个非阻塞的程序运行,所以它可以决定运行 A 直到 A 完成工作;它可以运行 B 直到 B 完成工作;最后运行 C。
这样的顺序不会导致死锁(因为不存在对资源的竞争),但是这种情况也完全没有并行性。进程除了在请求和释放资源外,还要做计算和输入/输出的工作。当进程按照顺序运行时,在等待一个 I/O 时,另一个进程不能使用 CPU。所以,严格按照串行的顺序执行并不是最优越的。另一方面,如果没有进程在执行任何 I/O 操作,那么最短路径优先作业会优于轮转调度,所以在这种情况下串行可能是最优越的
现在我们假设进程会执行计算和 I/O 操作,所以轮询调度是一种合理的调度算法。资源请求可能会按照下面这个顺序进行

下图是针对上面这六个步骤的资源分配图。
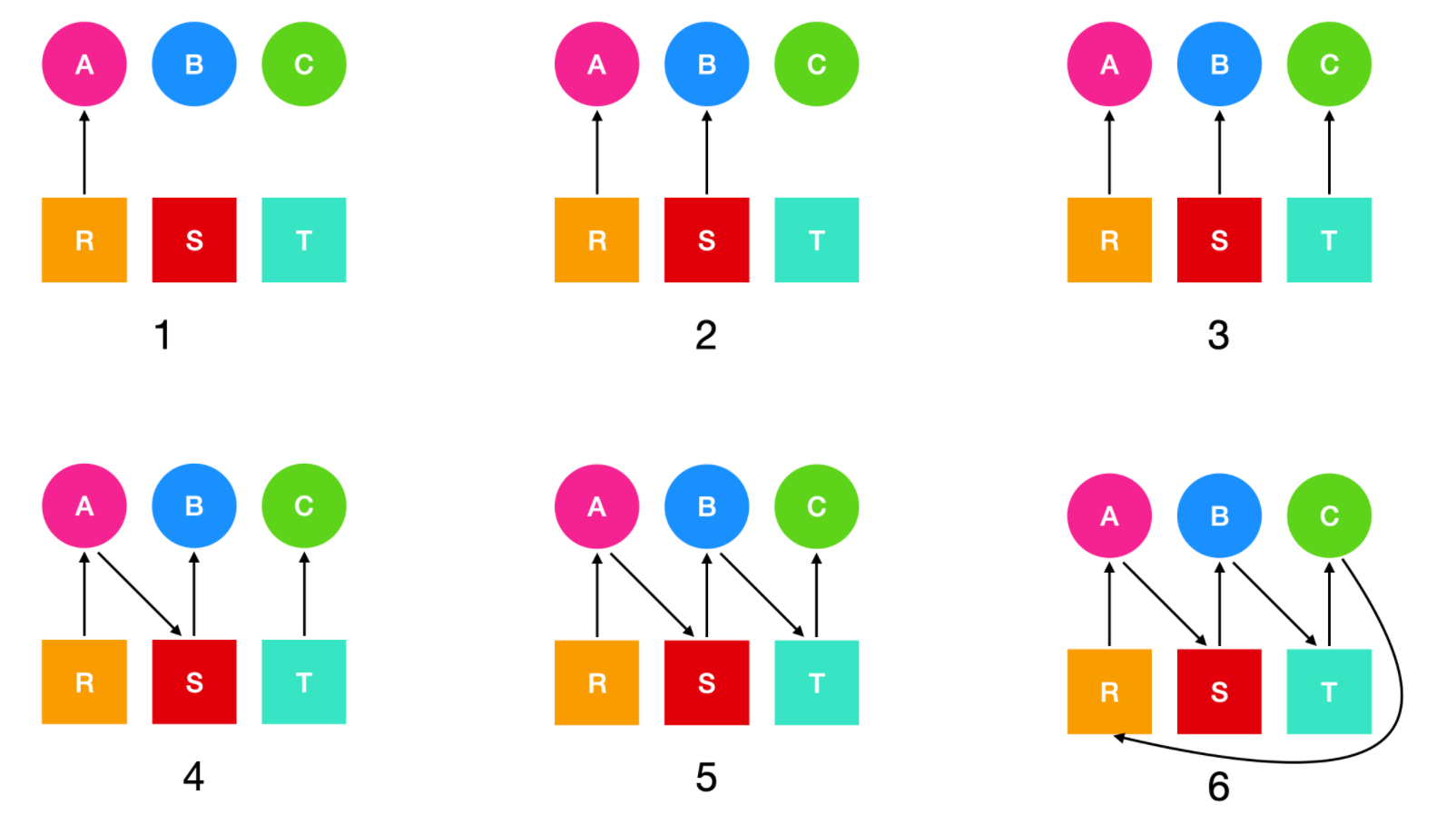
这里需要注意一个问题,为什么从资源出来的有向图指向了进程却表示进程请求资源呢?笔者刚开始看也有这个疑问,但是想了一下这个意思解释为进程占用资源比较合适,而进程的有向图指向资源表示进程被阻塞的意思。
在上面的第四个步骤,进程 A 正在等待资源 S;第五个步骤中,进程 B 在等待资源 T;第六个步骤中,进程 C 在等待资源 R,因此产生了环路并导致了死锁。
然而,操作系统并没有规定一定按照某种特定的顺序来执行这些进程。遇到一个可能会引起死锁的线程后,操作系统可以干脆不批准请求,并把进程挂起一直到安全状态为止。比如上图中,如果操作系统认为有死锁的可能,它可以选择不把资源 S 分配给 B ,这样 B 被挂起。这样的话操作系统会只运行 A 和 C,那么资源的请求和释放就会是下面的步骤

下图是针对上面这六个步骤的资源分配图。
在第六步执行完成后,可以发现并没有产生死锁,此时就可以把资源 S 分配给 B,因为 A 进程已经执行完毕,C 进程已经拿到了它想要的资源。进程 B 可以直接获得资源 S,也可以等待进程 C 释放资源 T 。
有四种处理死锁的策略:
- 忽略死锁带来的影响(惊呆了)
- 检测死锁并回复死锁,死锁发生时对其进行检测,一旦发生死锁后,采取行动解决问题
- 通过仔细分配资源来避免死锁
- 通过破坏死锁产生的四个条件之一来避免死锁
下面我们分别介绍一下这四种方法
鸵鸟算法
最简单的解决办法就是使用鸵鸟算法(ostrich algorithm),把头埋在沙子里,假装问题根本没有发生。每个人看待这个问题的反应都不同。数学家认为死锁是不可接受的,必须通过有效的策略来防止死锁的产生。工程师想要知道问题发生的频次,系统因为其他原因崩溃的次数和死锁带来的严重后果。如果死锁发生的频次很低,而经常会由于硬件故障、编译器错误等其他操作系统问题导致系统崩溃,那么大多数工程师不会修复死锁。
死锁检测和恢复
第二种技术是死锁的检测和恢复。这种解决方式不会尝试去阻止死锁的出现。相反,这种解决方案会希望死锁尽可能的出现,在监测到死锁出现后,对其进行恢复。下面我们就来探讨一下死锁的检测和恢复的几种方式
每种类型一个资源的死锁检测方式
每种资源类型都有一个资源是什么意思?我们经常提到的打印机就是这样的,资源只有打印机,但是设备都不会超过一个。
可以通过构造一张资源分配表来检测这种错误,比如我们上面提到的
的算法来检测从 P1 到 Pn 这 n 个进程中的死锁。假设资源类型为 m,E1 代表资源类型1,E2 表示资源类型 2 ,Ei 代表资源类型 i (1 <= i <= m)。E 表示的是 现有资源向量(existing resource vector),代表每种已存在的资源总数。
现在我们就需要构造两个数组:C 表示的是当前分配矩阵(current allocation matrix) ,R 表示的是 请求矩阵(request matrix)。Ci 表示的是 Pi 持有每一种类型资源的资源数。所以,Cij 表示 Pi 持有资源 j 的数量。Rij 表示 Pi 所需要获得的资源 j 的数量
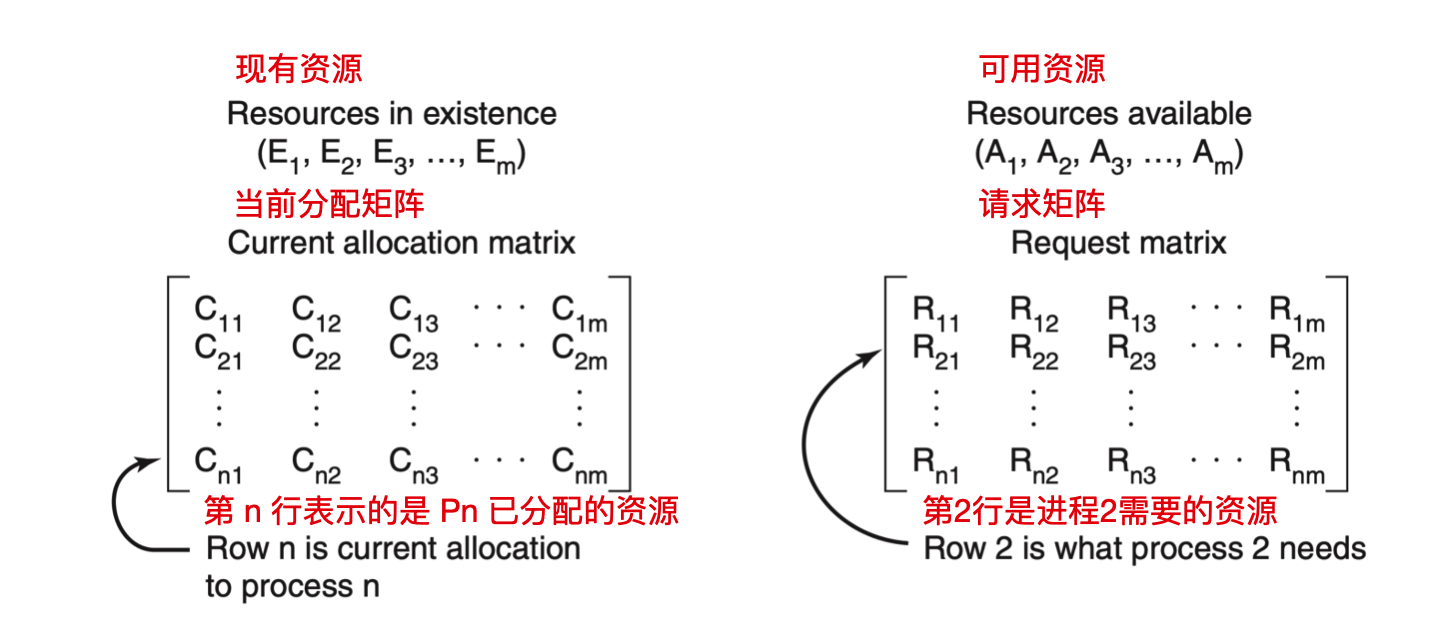
一般来说,已分配资源 j 的数量加起来再和所有可供使用的资源数相加 = 该类资源的总数。
死锁的检测就是基于向量的比较。每个进程起初都是没有被标记过的,算法会开始对进程做标记,进程被标记后说明进程被执行了,不会进入死锁,当算法结束时,任何没有被标记过的进程都会被判定为死锁进程。
上面我们探讨了两种检测死锁的方式,那么现在你知道怎么检测后,你何时去做死锁检测呢?一般来说,有两个考量标准:
- 每当有资源请求时就去检测,这种方式会占用昂贵的 CPU 时间。
- 每隔 k 分钟检测一次,或者当 CPU 使用率降低到某个标准下去检测。考虑到 CPU 效率的原因,如果死锁进程达到一定数量,就没有多少进程可以运行,所以 CPU 会经常空闲。
从死锁中恢复
上面我们探讨了如何检测进程死锁,我们最终的目的肯定是想让程序能够正常的运行下去,所以针对检测出来的死锁,我们要对其进行恢复,下面我们会探讨几种死锁的恢复方式
通过抢占进行恢复
在某些情况下,可能会临时将某个资源从它的持有者转移到另一个进程。比如在不通知原进程的情况下,将某个资源从进程中强制取走给其他进程使用,使用完后又送回。这种恢复方式一般比较困难而且有些简单粗暴,并不可取。
通过回滚进行恢复
如果系统设计者和机器操作员知道有可能发生死锁,那么就可以定期检查流程。进程的检测点意味着进程的状态可以被写入到文件以便后面进行恢复。检测点不仅包含存储映像(memory image),还包含资源状态(resource state)。一种更有效的解决方式是不要覆盖原有的检测点,而是每出现一个检测点都要把它写入到文件中,这样当进程执行时,就会有一系列的检查点文件被累积起来。
为了进行恢复,要从上一个较早的检查点上开始,这样所需要资源的进程会回滚到上一个时间点,在这个时间点上,死锁进程还没有获取所需要的资源,可以在此时对其进行资源分配。
杀死进程恢复
最简单有效的解决方案是直接杀死一个死锁进程。但是杀死一个进程可能照样行不通,这时候就需要杀死别的资源进行恢复。
另外一种方式是选择一个环外的进程作为牺牲品来释放进程资源。
死锁避免
我们上面讨论的是如何检测出现死锁和如何恢复死锁,下面我们探讨几种规避死锁的方式
单个资源的银行家算法
银行家算法是 Dijkstra 在 1965 年提出的一种调度算法,它本身是一种死锁的调度算法。它的模型是基于一个城镇中的银行家,银行家向城镇中的客户承诺了一定数量的贷款额度。算法要做的就是判断请求是否会进入一种不安全的状态。如果是,就拒绝请求,如果请求后系统是安全的,就接受该请求。
比如下面的例子,银行家一共为所有城镇居民提供了 15 单位个贷款额度,一个单位表示 1k 美元,如下所示
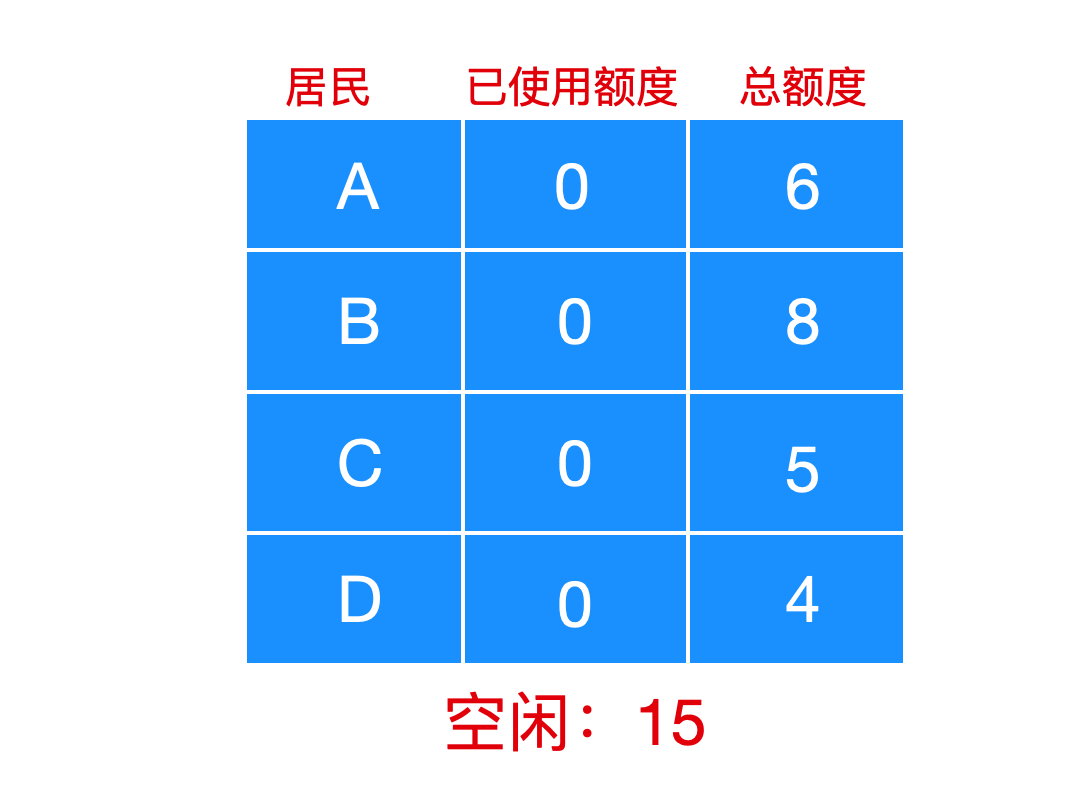
城镇居民都喜欢做生意,所以就会涉及到贷款,每个人能贷款的最大额度不一样,在某一时刻,A/B/C/D 的贷款金额如下
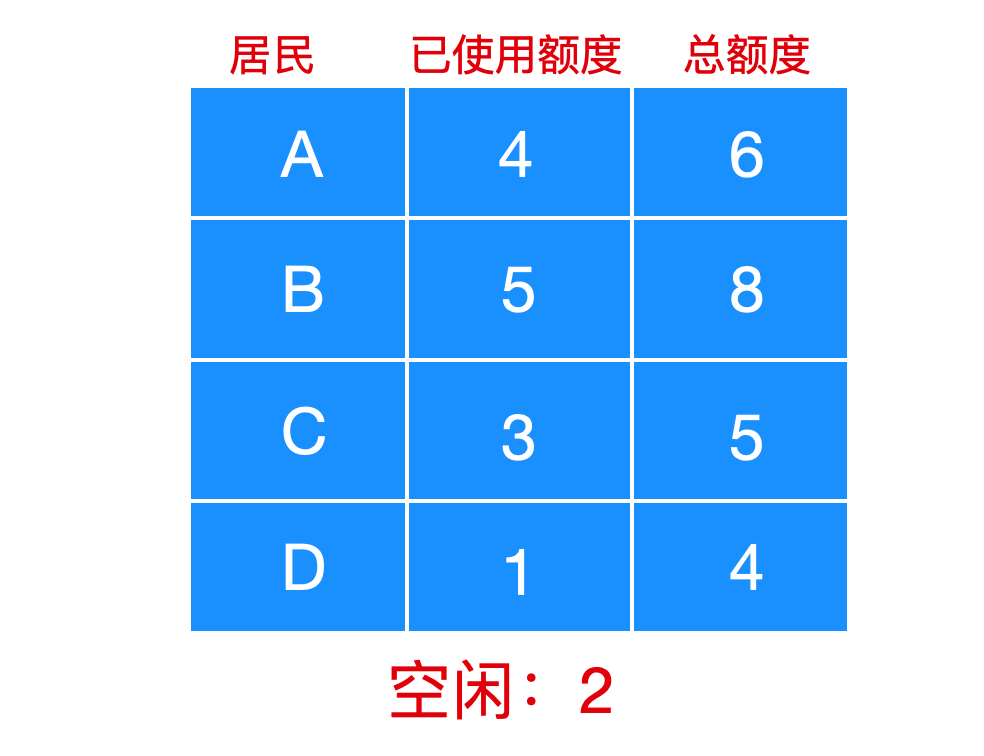
上面每个人的贷款总额加起来是 13,马上接近 15,银行家只能给 A 和 C 进行放贷,可以拖着 B 和 D、所以,可以让 A 和 C 首先完成,释放贷款额度,以此来满足其他居民的贷款。这是一种安全的状态。
如果每个人的请求导致总额会超过甚至接近 15 ,就会处于一种不安全的状态,如下所示
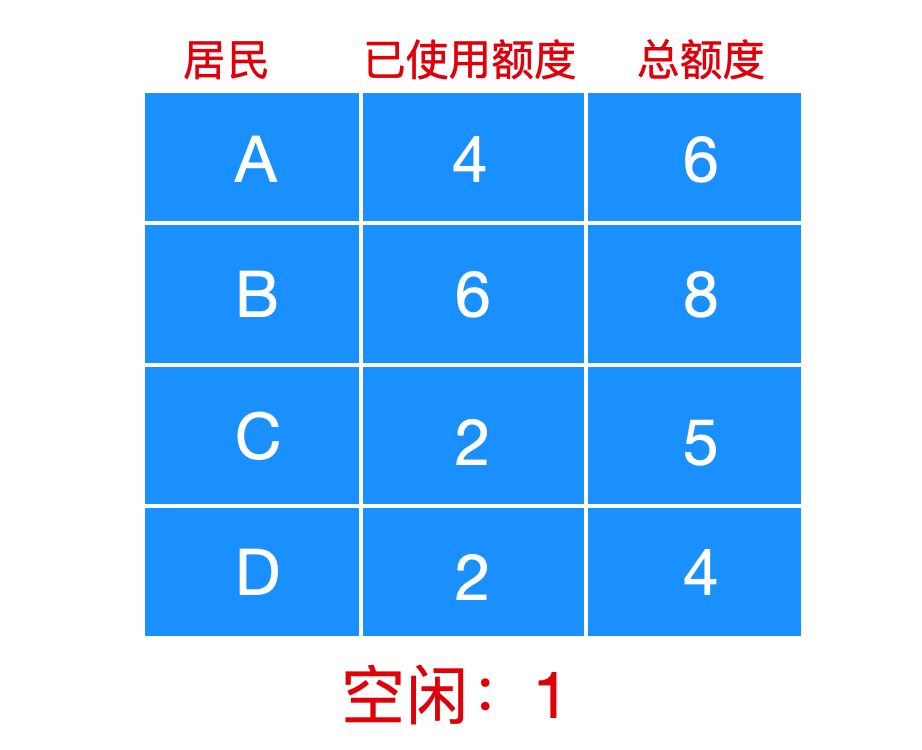
这样,每个人还能贷款至少 2 个单位的额度,如果其中有一个人发起最大额度的贷款请求,就会使系统处于一种死锁状态。
这里注意一点:不安全状态并不一定引起死锁,由于客户不一定需要其最大的贷款额度,但是银行家不敢抱着这种侥幸心理。
银行家算法就是对每个请求进行检查,检查是否请求会引起不安全状态,如果不会引起,那么就接受该请求;如果会引起,那么就推迟该请求。
类似的,还有多个资源的银行家算法,读者可以自行了解。
破坏死锁
死锁本质上是无法避免的,因为它需要获得未知的资源和请求,但是死锁是满足四个条件后才出现的,它们分别是
- 互斥
- 保持和等待
- 不可抢占
- 循环等待
我们分别对这四个条件进行讨论,按理说破坏其中的任意一个条件就能够破坏死锁
破坏互斥条件
我们首先考虑的就是破坏互斥使用条件。如果资源不被一个进程独占,那么死锁肯定不会产生。如果两个打印机同时使用一个资源会造成混乱,打印机的解决方式是使用 假脱机打印机(spooling printer) ,这项技术可以允许多个进程同时产生输出,在这种模型中,实际请求打印机的唯一进程是打印机守护进程,也称为后台进程。后台进程不会请求其他资源。我们可以消除打印机的死锁。
后台进程通常被编写为能够输出完整的文件后才能打印,假如两个进程都占用了假脱机空间的一半,而这两个进程都没有完成全部的输出,就会导致死锁。
因此,尽量做到尽可能少的进程可以请求资源。
破坏保持等待的条件
第二种方式是如果我们能阻止持有资源的进程请求其他资源,我们就能够消除死锁。一种实现方式是让所有的进程开始执行前请求全部的资源。如果所需的资源可用,进程会完成资源的分配并运行到结束。如果有任何一个资源处于频繁分配的情况,那么没有分配到资源的进程就会等待。
很多进程无法在执行完成前就知道到底需要多少资源,如果知道的话,就可以使用银行家算法;还有一个问题是这样无法合理有效利用资源。
还有一种方式是进程在请求其他资源时,先释放所占用的资源,然后再尝试一次获取全部的资源。
破坏不可抢占条件
破坏不可抢占条件也是可以的。可以通过虚拟化的方式来避免这种情况。
破坏循环等待条件
现在就剩最后一个条件了,循环等待条件可以通过多种方法来破坏。一种方式是制定一个标准,一个进程在任何时候只能使用一种资源。如果需要另外一种资源,必须释放当前资源。对于需要将大文件从磁带复制到打印机的过程,此限制是不可接受的。
另一种方式是将所有的资源统一编号,如下图所示

进程可以在任何时间提出请求,但是所有的请求都必须按照资源的顺序提出。如果按照此分配规则的话,那么资源分配之间不会出现环。
尽管通过这种方式来消除死锁,但是编号的顺序不可能让每个进程都会接受。
其他问题
下面我们来探讨一下其他问题,包括 通信死锁、活锁是什么、饥饿问题和两阶段加锁
两阶段加锁
虽然很多情况下死锁的避免和预防都能处理,但是效果并不好。随着时间的推移,提出了很多优秀的算法用来处理死锁。例如在数据库系统中,一个经常发生的操作是请求锁住一些记录,然后更新所有锁定的记录。当同时有多个进程运行时,就会有死锁的风险。
一种解决方式是使用 两阶段提交(two-phase locking)。顾名思义分为两个阶段,一阶段是进程尝试一次锁定它需要的所有记录。如果成功后,才会开始第二阶段,第二阶段是执行更新并释放锁。第一阶段并不做真正有意义的工作。
如果在第一阶段某个进程所需要的记录已经被加锁,那么该进程会释放所有锁定的记录并重新开始第一阶段。从某种意义上来说,这种方法类似于预先请求所有必需的资源或者是在进行一些不可逆的操作之前请求所有的资源。
不过在一般的应用场景中,两阶段加锁的策略并不通用。如果一个进程缺少资源就会半途中断并重新开始的方式是不可接受的。
通信死锁
我们上面一直讨论的是资源死锁,资源死锁是一种死锁类型,但并不是唯一类型,还有通信死锁,也就是两个或多个进程在发送消息时出现的死锁。进程 A 给进程 B 发了一条消息,然后进程 A 阻塞直到进程 B 返回响应。假设请求消息丢失了,那么进程 A 在一直等着回复,进程 B 也会阻塞等待请求消息到来,这时候就产生死锁。
尽管会产生死锁,但是这并不是一个资源死锁,因为 A 并没有占据 B 的资源。事实上,通信死锁并没有完全可见的资源。根据死锁的定义来说:每个进程因为等待其他进程引起的事件而产生阻塞,这就是一种死锁。相较于最常见的通信死锁,我们把上面这种情况称为通信死锁(communication deadlock)。
通信死锁不能通过调度的方式来避免,但是可以使用通信中一个非常重要的概念来避免:超时(timeout)。在通信过程中,只要一个信息被发出后,发送者就会启动一个定时器,定时器会记录消息的超时时间,如果超时时间到了但是消息还没有返回,就会认为消息已经丢失并重新发送,通过这种方式,可以避免通信死锁。
但是并非所有网络通信发生的死锁都是通信死锁,也存在资源死锁,下面就是一个典型的资源死锁。
当一个数据包从主机进入路由器时,会被放入一个缓冲区,然后再传输到另外一个路由器,再到另一个,以此类推直到目的地。缓冲区都是资源并且数量有限。如下图所示,每个路由器都有 10 个缓冲区(实际上有很多)。
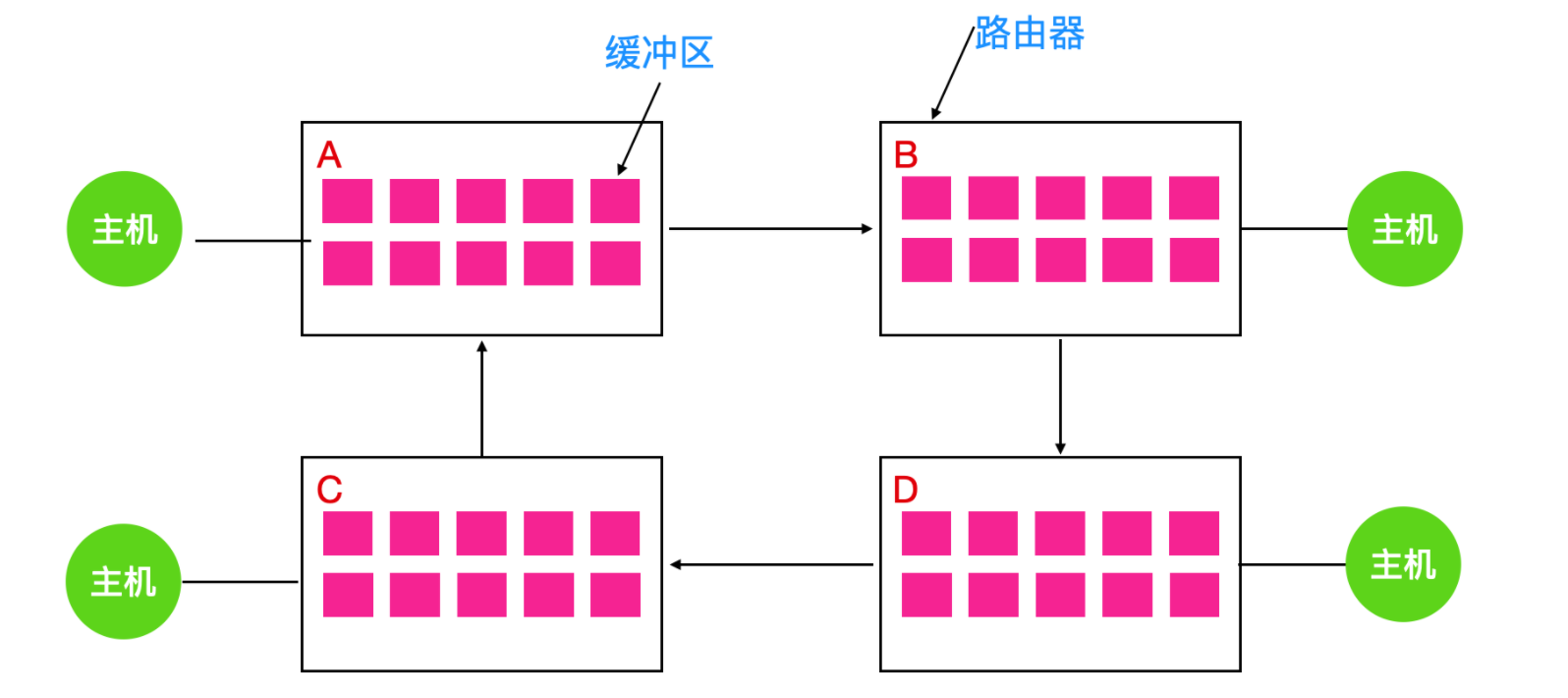
假如路由器 A 的所有数据需要发送到 B ,B 的所有数据包需要发送到 D,然后 D 的所有数据包需要发送到 A 。没有数据包可以移动,因为在另一端没有缓冲区可用,这就是一个典型的资源死锁。
活锁
你会发现一个很有意思的事情,死锁就跟榆木脑袋一样,不会转弯。我看过古代的一则故事:

如果说死锁很痴情的话,那么活锁用一则成语来表示就是 弄巧成拙。
某些情况下,当进程意识到它不能获取所需要的下一个锁时,就会尝试礼貌的释放已经获得的锁,然后等待非常短的时间再次尝试获取。可以想像一下这个场景:当两个人在狭路相逢的时候,都想给对方让路,相同的步调会导致双方都无法前进。
现在假想有一对并行的进程用到了两个资源。它们分别尝试获取另一个锁失败后,两个进程都会释放自己持有的锁,再次进行尝试,这个过程会一直进行重复。很明显,这个过程中没有进程阻塞,但是进程仍然不会向下执行,这种状况我们称之为 活锁(livelock)。
饥饿
与死锁和活锁的一个非常相似的问题是 饥饿(starvvation)。想象一下你什么时候会饿?一段时间不吃东西是不是会饿?对于进程来讲,最重要的就是资源,如果一段时间没有获得资源,那么进程会产生饥饿,这些进程会永远得不到服务。
我们假设打印机的分配方案是每次都会分配给最小文件的进程,那么要打印大文件的进程会永远得不到服务,导致进程饥饿,进程会无限制的推后,虽然它没有阻塞。
总结
死锁是一类通用问题,任何操作系统都会产生死锁。当每一组进程中的每个进程都因等待由该组的其他进程所占有的资源而导致阻塞,死锁就发生了。这种情况会使所有的进程都处于无限等待的状态。
死锁的检测和避免可以通过安全和不安全状态来判断,其中一个检测方式就是银行家算法;当然你也可以使用鸵鸟算法对死锁置之不理,但是你肯定会遭其反噬。
也可以在设计时通过系统结构的角度来避免死锁,这样能够预防死锁;也可以破坏死锁的四个条件来破坏死锁。资源死锁并不是唯一性的死锁,还有通信间死锁,可以设置适当的超时时间来完成。
活锁和死锁的问题有些相似,它们都是一种进程无法继续向下执行的状态。由于进程调度策略导致尝试获取进程的一方永远无法获得资源后,进程会导致饥饿的出现。




